Aries: A Transaction Recovery Method
2023-12-30

原文:https://cs.stanford.edu/people/chrismre/cs345/rl/aries.pdf
Aries描述了一个数据库Recovery算法,用以保证事务的【A】和【D】,主要包括俩部分:
- Runtime时的协议。包括WAL、checkpoint、steal、no-force等
- Recovery时的协议。包括状态重建、回滚算法等。
steal?force?
Aries算法建立在Page模型数据库上。一个Page要么在磁盘上,要么同时存在磁盘和内存上,如果内存上的数据和磁盘上的数据不一致,则称其未Dirty Page。 内存中的Page由Buffer Manager管理,决定什么时候换出到磁盘以及换入到内存。(不多赘述 对于Page的换出换入,有多种策略:
- steal:还没有提交的事务写的数据也能被写入磁盘。Runtime友好
- no-steal:写入磁盘的数据必须是已提交事务写入的
- force:事务提交时必须将其所有改动写入磁盘。Recovery友好
- no-force:事务提交不必马上将改动写入磁盘
steal能让Buffer Manager的调度更加自由,且能提供更高的吞吐,如果有一百个事务都修改了同一个Page,如果采用no-steal策略,必须等这一百个事务都commit了,这个Page才能写盘;更糟糕的情况,如果一直都有事务来写这个page,那这个page就一直刷不了盘了。除非隔段时间lock住页面,禁止所有新事务都写入并等待已有事务全部提交。这显然会影响吞吐。
Aries选用的是steal+no-force,这是runtime性能最好的一个方案,也是大多数数据库的选择。
术语
Aries中的概念非常多…第一次看很难记得住。
- BM:Buffer Manager:管理内存中的Page,并决定其换出换入
- Log Record:一条日志记录。Aries中提及的Log Record有三种:
- redo log:记录事务对数据页的修改操作,当数据库crash需要recover时,可以逐条redo log来对页面进行replay,还原出crash时系统的状态。因为Aries采用的是no-force策略,事务提交时不强制刷新脏页,为了保证数据不丢失,会要求事务的redo log必须刷盘。
- undo log:记录回滚一个事务修改所需要的信息。因为aries采用steal策略,磁盘上的数据可能是还未提交的数据。recover时,需要知道怎么把这些数据还原回去。
- CLR:Compensation Log Record。aries中的undo log是逻辑日志,而CLR可以认为是undo log的物理执行;或者说是undo log恢复时的redo log;还有一个功能是记录当前undo的进度,因为逻辑undo log是非幂等的,所以必须又一个地方记录undo执行到了什么位置。
- LSN:Log的序号,单调递增,标识一个log
- Prev LSN:Log Record的一个属性,记录同一事务的上一条log。因为一个事务的log不一定在物理上连续。依赖这个字段构建出一个事务的log列表。
- Page LSN:Page的一个属性,最近一次修改这个Page的Log对应的LSN。
- Rec LSN:Page的属性。上一次刷盘后,第一次修改Page的Log LSN。根据这个来判断需要从哪里开始redo
- Last LSN:事务的属性。事务的最新一个更新操作的Log LSN
- UndoNext LSN:只存在于CLR中,记录下一条应该执行的undo log。(前面说明CLR有记录undo进度的作用
- DPT:Dirty Page Table。记录所有的Dirty Page及其Rec LSN。Recover时以此来redo
- ATT:Active Transaction Table。记录了活跃事务以其对应的Last LSN。Recover时以此来undo
逻辑日志or物理日志
物理日志数据量大但具备恢复速度快(因为不需要依赖数据库的元数据来恢复)和具备幂等性的特点。 逻辑日志数据量小,但恢复时依赖元数据。
Redo log需要是物理日志,因为单个逻辑操作对应的数据更新不是原子的。比如插入一条数据可能导致Page分裂成两个,但其中一个落盘了,然后crash。此时根据逻辑redo无法恢复出正确结果。 而且物理Redo log的好处是在redo时做到page级别的并行恢复。
而逻辑Undo log有利于并行度。假设undo log是物理的,那么在这个事务提交之前,该事务涉及的page不能分裂,否则物理undo log记录的内容将失效。这一规则限制了其他事务的进行。
Aries使用物理Redo日志和逻辑Undo日志。
DPT & ATT
DPT(Dirty Page Table):记录脏页面及其对应的Rec Log。由BM管理,每次把Page从磁盘加载内存中时,需要在DPT中插入一条数据指向这个页面;同理,flush成功后,从DPT中删除这项
ATT(Active Transaction Table):活跃事务表,记录了活跃事务以其对应的Last LSN、UndoNext LSN。如果Last Log不是CLR,那么Last LSN和UndoNext LSN一样;否则UndoNext LSN就是CLR中记录的UndoNext LSN。所以这里的信息是为了标识Undo要从哪里开始执行
Runtime行为
事务写操作:
- 请求写入Page,BM发现Page不在内存中,则从磁盘调出,同时记录DPT。
- 对页面加latch,修改页面,记录Undo和Redo
- 更新ATT
- 解latch
Page换出:
- 更新Page的Page LSN,后面Redo的时候跳过LSN <= Page LSN的日志
- DPT删除对应项
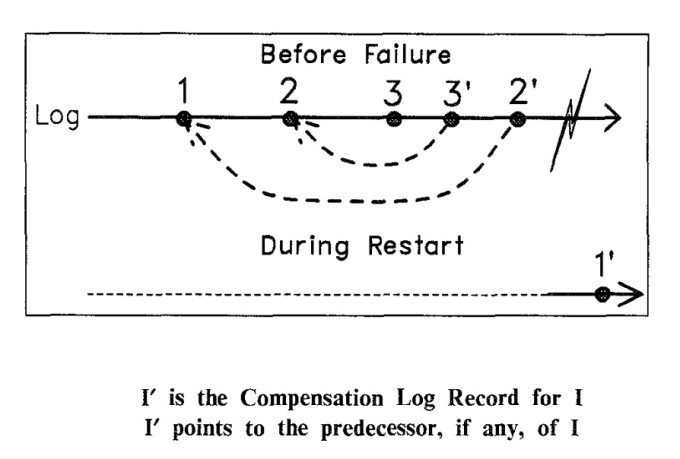
Rollback:
- 从ATT找到该事务的UndoNext LSN,从这里开始往前依次处理Undo,如果遇到不是Redo就跳过。处理完Undo后,要追加写一条CLR,CLR.UndoNxtLog = CurUndoLog.PrevLSN
- 全部处理完毕后,记一个end log
如图所示:
Recovery行为
Aries算法会记录一个checkpoint日志,记录当前的ATT和DPT,用以crash时的恢复。并且会有一个持久化的master record指向这个checkpoint日志对应的位置(具体怎么记这个checkpoint,后面说。
Recovery分三个阶段:
- Analysis Pass
- Redo Pass
- Undo Pass
Analysis Pass
目的是恢复出crash前系统的DPT和ATT。(涉及到checkpoint,后面讲,这一步的结果就是如此
Redo Pass
上一阶段完成后,已经得到了DPT和ATT。根据DPT做Redo,对于Redo Log LSN <= Page LSN的log可以直接跳过(这里不同的page redo其实可以并行
这一步执行完后,数据库就可以对外服务了。
Undo Pass
上一阶段完成后,系统就恢复到了crash前的状态。此时需要对未完成的事务进行undo,恢复到一个"干净"的状态。主要是通过ATT
在处理完每个Undo Log后,要追加写一条CLR,CLR.UndoNxtLog = CurUndoLog.PrevLSN。这样,如果undo到一半又crash了,那么可以找到CLR,找到之前的进度继续处理。避免了逻辑Undo日志非幂等的问题
(不同的txn undo 可以并行
CheckPoint
Redo和Undo日志不能无休止地增长下去。需要有垃圾回收的机制,回收不再会被用到的log。什么时候我们可以认为其不再会被用到呢?如果一个事务已经提交,且其写过的page全部都落盘,那么其产生的undo和redo日志就不再需要了。所以我们希望有一个checkpoint机制,checkpoint之前的日志可以被安全清理。 但是系统是一直在运转的,怎么才能得到一个checkpoint?一个方法是停止对外服务,等待当前所有活跃事务结束和脏页刷新,然后记录一条checkpoint log,在此之前的日志就可以被回收了。然后再重新对外服务。
aries提出了在线checkpoint的方案:fuzzy checkpoint。在开始checkpoint时,记录一个checkpoint begin日志,然后开始序列化ATT和DPT的内容,再写到checkpoint end日志中。这样我们就可以通过checkpoint end日志中的记录,找到当前日志的低水位:比如说所有脏页中最小的Rec LSN之前的Redo日志是可以被安全清除的。 在Recovery时,从checkpoint begin日志开始往后扫日志,就能恢复出crash前ATT和DPT的状态: 从master record找到checkpoint begin,扫描到checkout end,获得ATT和DPT存量的状态,然后往后扫日志得到增量。比如说遇到了一个redo log,但是这个事务不在ATT中,那么将其加入;如果对应的page不在DPT中,也加入;如果遇到了一个end log,就将事务从ATT从移除。