ATC '23 Distributed Transactions at Scale in Amazon DynamoDB
2024-01-10
(论文第一章节就表明 我们DynamoDB和Dynamo没关系! 第二章节又提了一次我们名字差不多但架构完全不一样。233)
事务
Transactions are submitted as single request. DynamoDB不支持交互式事务,给出的原因是交互式事务往往是一个长事务,长时间持锁影响系统吞吐,而毕竟提供"predictable performance"是DynamoDB的一大设计原则。
DynamoDB所有的更新都是直接in-place,没实现MVCC,所以交互式事务对性能的影响会更大。
事务请求需要经过coordinator走2pc,非事务请求直接在存储节点执行
To simplify the design and take advantage of low-contention workloads,
DynamoDB uses an optimistic concurrency control scheme that avoids locking altogether.
DynamoDB采用乐观并发控制 OCC
用户接口上,提供了非事务的GetItem、PutItem、DeleteItem、UpdateItem接口,以及TransactGetItems和TransactWriteItems的事务接口。
其中TransactGetItems会提供一个一致性的快照视图,如果执行过程中遇到了写冲突会直接返回失败。
The TransactWriteItems may optionally include one or more preconditions on current values of the items.
DynamoDB rejects the TransactWriteItems request if any of the preconditions are not met.
TransactWriteItems支持跨表事务,且支持condition写,文中给了一个用户下单的事务场景,其中的condition就是校验用户是否存在

Timestamp Ordering
每个coordinator的时钟由AWS time-sync service分配,会有a few microseconds的误差。每个事务由其所在的coordinator节点分配事务ts,没有做commit-wait、read-wait之类。文中认为本地时钟也可以实现serializability,只不过更准确的时钟可以达到更高的事务成功率,以及事务的执行顺序更接近于事务发生时墙上时钟的顺序。
Although serializability holds even if the transaction coordinators do not have synchronized clocks,
more accurate clocks result in more successful transactions and a serialization order that complies with real time.
write transaction protocol
item上存储一个write-ts,代表这个item最后一个更新事务的commit-ts。 除此之外,还在partition纬度维护一个max-delete-ts。因为如果对item的最新操作是一个删除,那么item没了自然也就没有write-ts了,所以需要额外记录一个delete-ts。
DynamoDB也采用2PC模型。prepare阶段存储节点主要在做以下检查:
- 所有的precondition需要满足
- 事务ts要大于写入item的write-ts
- 如果插入一个空的item,事务ts需要 > partition-max-delete-ts
- 没有其他prepare状态的先前事务正在准备写入这个item

(其实这里我有一点小疑问:这段伪代码展示的是对写入item的precondition,但上文的下单例子中展示的其实是"check A then write B",那是不是得先去A加个读锁之类的,如果是的话那这段伪代码的逻辑会有一些改动。但论文没讲,似乎默认就是只能check和write同一个item,但举的例子又不是,fine…
所有prepare成功后,再向所有参与者发起commit,全部成功后响应客户端。(看起来没有异步resolve或者parallel commit之类的优化

read transaction protocol
经典的Timestamp Order 会对每个item维护一个read-ts,代表最新一个读到这个item的事务ts。但缺点是读会引入写。 DynamoDB为了避免这个额外的写,采用了两阶段读。
第一个阶段,存储节点处理读操作,如果要读的item上有已经prepared的写事务,返回失败。否则存储节点除了返回value外,还携带这个item的LSN,标识着最后一次写入(直接返回write-ts不是就可以吗?不是很get到为什么引入了一个LSN
第二个阶段就是校验LSN是否改变。若没有,则等价于两阶段内上了写锁。
Recovery and fault tolerance
参与者的failure并不是一个大问题,因为它有一个replication group,leadership很快就会被转移到其他节点上然后继续处理事务。
而coordinator的failure是个问题。DynamoDB会有一个专门的事务表用以记录事务的状态,然后recovery-manager模块会周期性地扫描这个表上的事务,当一个事务过长时间没有进展时,recovery-manager会将这个事务重新assign给一个另一个coordinator,由后者来继续推进事务。
这个时候可能出现的一种情况是同时有两个coordinator在处理同一个事务,DynamoDB认为it‘s ok,重复的请求会被忽视掉。
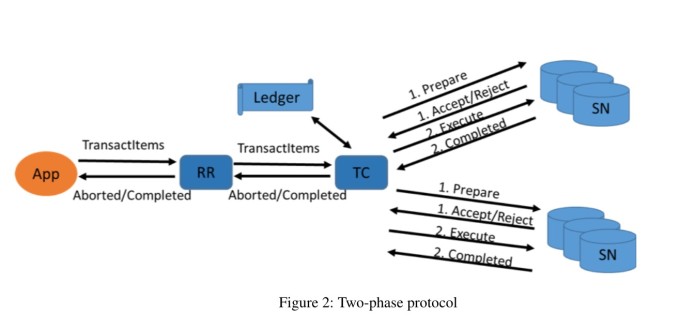
如果只是这样的话,那这里其实有一个问题,那就是coordinator一阶段写入成功,然后挂掉了,那么后续所有写入都会因为看到这个item上的ongoingTransaction而失败。那啥时候能恢复呢?取决于recovery-manager扫描事务表的period有多久。所以参与者发现prepared过久没有commit或者abort后也会主动去触发recovery,
Adapting timestamp ordering
前三章说的东西挺朴素的,就是一个基本分布式事务的实现套路,所以论文第四章也提了一些优化
Point Get一定会成功
即使要读的item上面的ongoingTransaction不为空,也可以直接返回最新的数据,而不是返回失败。
这里相当于这个Point Get被隐式赋予了一个ts,这个ts大于已提交的事务ts,小于ongoingTransaction的ts。
这里其实和上面的同步2pc(等所有的item都resolve成功才返回给客户端成功,而不是异步resolve)有点关系。因为如果是异步resolve的话,读到ongoingTransaction还返回旧数据的话会破坏线性一致性(比如说ongoingTransaction实际上已经完成了,这个item正在等待异步resolve,然后你这个时候却给读返回了一个旧数据
而所有东西同步的话就能这么搞,因为看到ongoingTransaction说明肯定还没返回给客户端。
Point Put有些情况下可以直接成功
如果put时候发现item上有ongoingTransaction,也可以直接成功,相当于被序列化到了最新的数据之后、ongoingTransaction之前。这个ongoingTransaction如果提交的话,会将这个point put的数据覆盖。
但这么做有一个前提,那就是这个Point Put不会破坏这个ongoingTransaction的precondition。(那怎么检查这个条件呢?这个precondition是不是得上个锁。。没讲
冲突的Point Put不需要马上失败
即使这个Point Put会破坏ongoingTransaction的precondition,也不需要直接拒绝,而是可以buffer住然后排队,被序列化到这个ongoingTransaction之后执行
如果最新的写入是一个覆盖写,那么持有旧ts的Write transactions也可以写入成功
类似于Thomas Write Rule。但如果最新写入是一个部分更新,就不适用。
对同一item的多个写事务可以被同时prepared
Multiple transactions that write the same item may be prepared at the same time.
A storage node that has already prepared a transaction can accept a second transaction that is attempting to write the same item
一个item如果已经接受了一个ongoingTransaction的prepare,那么其也可以接受另一个事务的prepare,最后提交的时候排队。
这个感觉很tricky,细节估计很难处理。。。
读事务可以忽略两阶段读
使用GetItemWithTimestamp而不是GetItem就可以避免两阶段读。
如果其比最新的数据的write-ts大,且比ongoingTransaction的ts要小,则可以直接返回最新的数据。否则返回失败。
这样会有一个问题那就是读事务执行完后,会有一个比它的ts更小的事务写入这个item,这会破坏序列化。
DynamoDB在这个item上记录一个读取时间戳read-ts,避免后续ts<read-ts的写事务写入成功。
(什么?我没看错吧,不是你自己说TO的读会带来写所以你采用两阶段读吗。。。。
如果一个事务写入的项在一个分区,可以1PC执行
Obviously
优化:
- “减少项目与磁盘的交互” 美化成:发现了系统性能不足,自己排查发现是磁盘IO过多,确定了优化方案也就是加上了二级缓存,最后提升了性能(接口响应时间减少了40%,编一个) 怎么排查?: 1. go-pprof查看项目的调用栈,找到耗时的函数,发现就是读写磁盘的那个函数 https://cloud.tencent.com/developer/article/2108993 2. linux iostat命令 发现磁盘的响应时间确实很慢,压力比较大 https://www.cnblogs.com/zhongguiyao/p/13934226.html 3. 设计二级缓存方案,开发,得到结果,提升40%
一些可以编的功能开发:
1. redis大key拆分
包括怎么排查和怎么优化 https://zhuanlan.zhihu.com/p/622474134 https://zhuanlan.zhihu.com/p/537367637
2. redis令牌桶实现 分布式限流
令牌桶和漏斗算法区别:https://blog.csdn.net/weixin_37862824/article/details/124814827
java实现:https://juejin.cn/post/7054875996146630693
3. java对象池
1. 为什么需要?开发了一个新功能,发现内存占比很高,接口很慢
2. 排查发现,新引入的一个对象实例特别多。怎么排查发现?https://zhuanlan.zhihu.com/p/606574705 https://www.cnblogs.com/sxdcgaq8080/p/11089664.html
3. 引入对象池,复用对象,减少内存分配 https://juejin.cn/post/7107913254973734942