VLDB'19 Scalable GC for In-Memory MVCC Systems
2024-01-01
原文:https://users.cs.utah.edu/~pandey/courses/cs6530/fall22/papers/mvcc/p128-bottcher.pdf
问题
在使用MVCC技术的数据库上,长时间运行的事务可能会导致一种恶性循环
长事务导致历史版本垃圾不能被及时回收,同时不断有新事务产生新的数据版本,导致版本链越来越长,版本链变长会导致检索速度变慢,进而让原本就long-live的事务变得更long:
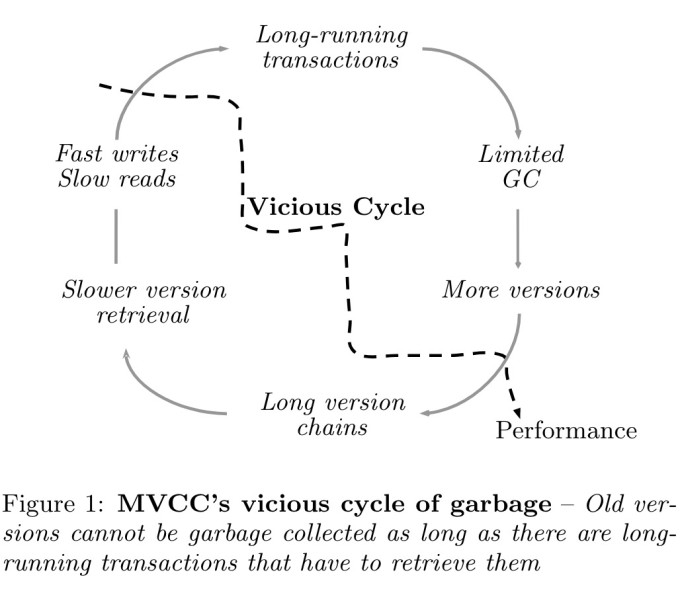
特别是对于HTAP workload,会存在一个长时间运行的AP查询。而为啥用长事务会影响历史版本的回收?因为很多GC策略都是基于当前活跃事务计算一个低水位ts,小于低水位的历史版本都可以被安全回收,不会破坏任何活跃事务的视图;亦或是epoch-base,按顺序回收epoch内的垃圾。
但这种"低水位"的方式都会导致一个问题,如果系统中有一个"很老的、跑了很久的"事务存在(比如一个大查询),就会影响低水位的计算。最坏的情况,如果这个长事务一直不结束,那么"低水位"就一直不会更新,导致gc无法进行:
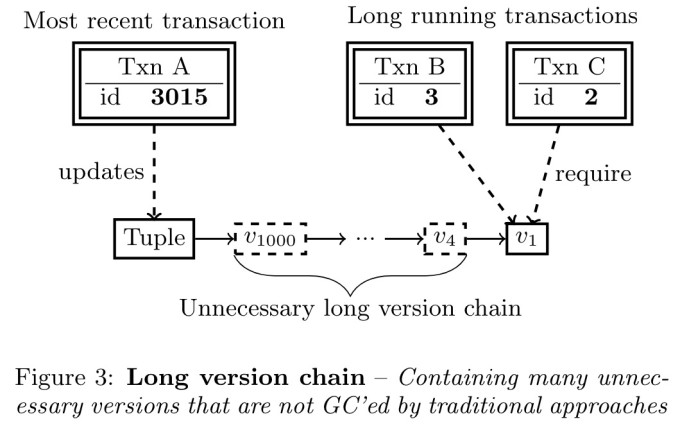
比如图中这种情况:该tuple已经产生了1000个历史数据,但是因为还有两个很老的事务需要看到v1版本的数据,导致水位不能更新,所以v2-v999之间的历史版本都不能回收(但实际上不会有任何活跃事务可以访问到它们
所以论文提出了一个叫Stream的垃圾回收方式来应对这种场景。
MVCC GC机制调查
论文从几个角度来评估一个数据库的GC策略:
- Tracking Level
- Frequency
- Version Storage
- Identifier
- Removal

这里其实不少地方都可以参考吴博士的论文An Empirical Evaluation of In-Memory Multi-Version Concurrency Control。
Tracking Level
其中Epoch和Txn Batch就是上述论文提到的Transaction-Level。我认为Txn Batch也是Epoch的一种,只是看以什么为标准来切割一个epoch。比如是一个固定的时间?还是一批事务?
然后这里的Transaction应该是类似于上述论文里的tuple-level中的coop。
Version Storage
Delta、Time Travel、O2N等概念,也在吴博士论文里有说,跳过。
这里主要说了一个点。要把历史数据版本存在什么地方呢?是全局的一个数据结构串起所有历史版本?还是在事务内部存一个undo log,然后不同事务里的undo log组成一个tuple的版本链? 论文认为全局数据结构的好处是GC时可以独立地回收每个单独的版本;但如果想以事务纬度来做精准地回收比较困难。比如说,现在想回收事务A产生的所有历史版本。在全局数据结构里就不好做,但如果是存在事务内部,很容易就能找到这个事务产生了哪些垃圾。
所以论文的Stream算法采用的是undo log
Identifier
就是说要以什么标准来衡量一个数据是否可以被GC。
如果事务会被单调递增时间戳来标识,那么就可以用时间戳来识别数据是否可以被回收。具体就是在活跃事务表中找到最老的一个活跃事务,其start_ts就是一个GC savepoint。但是缺点就如文章一开始所说那样,对于HTAP workload支持得不好,中间的数据版本无法被回收。
或者是基于epoch base。每个事务都会有一个所属的epoch,事务开始时自增一下所属epoch的计数器,事务结束时减一下,事务执行产生的垃圾数据也注册到epoch中。当一个epcoh的引用计数降为0且之前的epoch也已经被回收,那么这个epoch内产生的所有垃圾都可以被回收掉。
Removal
回收方式,Vaccum?事务协同?同样吴博士论文里有提,跳过。
Stream采用的是COOP方式。在事务执行过程中也会交叉执行GC的工作,会略微增加事务的负担,但对后续的读事务友好
设计
Stream GC也采用传统GC策略的数据结构:两个链表,一个串起活跃事务,一起串起提交事务。
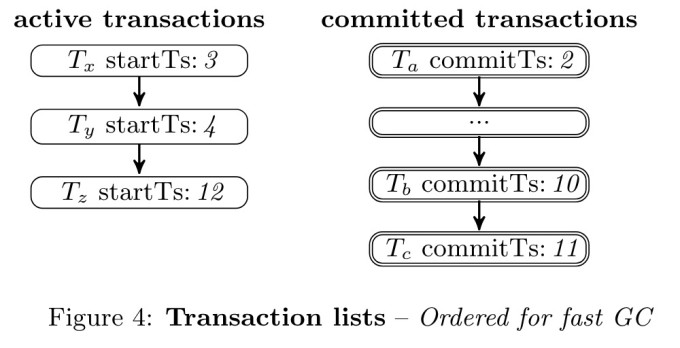
事务启动时被加到活跃事务链表中,commit后加到提交事务链表中。如果是只读事务就直接从活跃事务中移除。
这两个链表都是O2N,可以很快找到最老那个活跃事务的start_ts。然后去提交事务链表中遍历回收每一个事务的垃圾数据,直到遇到事务的commit ts > min start ts,就停下来。
另外,Stream GC是交叉在事务执行中的,当事务访问到了一个tuple,就会对这个tuple执行一下GC
但在此基础上,Stream GC主要解决俩问题:一个是Scalability,一个是HTAP workload。(其实还提到了第三个问题就是历史数据的内存优化,不过我觉得就是普通undo log的delta设计,就不专门写了。
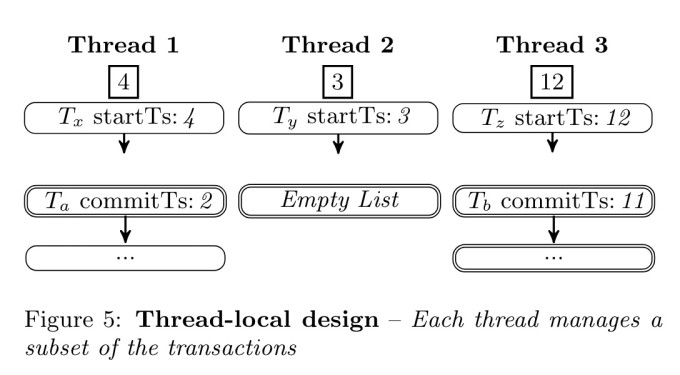
Scalability
对于Scalability,Stream GC采用thread local的方式,每个工作线程都有两个链表,每个线程各自维护一个全局事务的独立子集。并通过一个64位整数来共享本地的最老活跃事务的start ts。每个线程通过收集其他线程的min start ts,得到global min start ts
HTAP workload
提出了一种算法叫Eager Pruning of Obsolete Versions(EPO)。
获取一个全局的排好序的活跃事务列表,然后基于列表对历史版本进行修剪。核心思想就是清理活跃事务之间的垃圾数据,而不是只清理min start ts之前的数据

every thread periodically retrieves the start timestamps of the currently active transactions and stores them in a sorted list 这个全局排序的活跃事务列表是周期性获取的 ,也就是说不一定是最新的。(其实有点怀疑这里的overhead。获取一个全局的活跃事务列表是不是和前面说的Scalability有点冲突?