SOSP'13 Silo: Speedy transactions in multicore in-memory databases
2023-12-24
Motivation
多核系统中,单点瓶颈的存在使得数据库的扩展性下降。例如,为了保证事务的total order,往往存在一个中心的授时服务,在单机数据库中以一个fetch-and-add来实现,而这样的cas操作会锁内存总线,在多核系统中会成为一个单点瓶颈,影响scalibility,而在memory database中更是会成为bottle neck
在扩展到16+核心时,tps就上不去了:
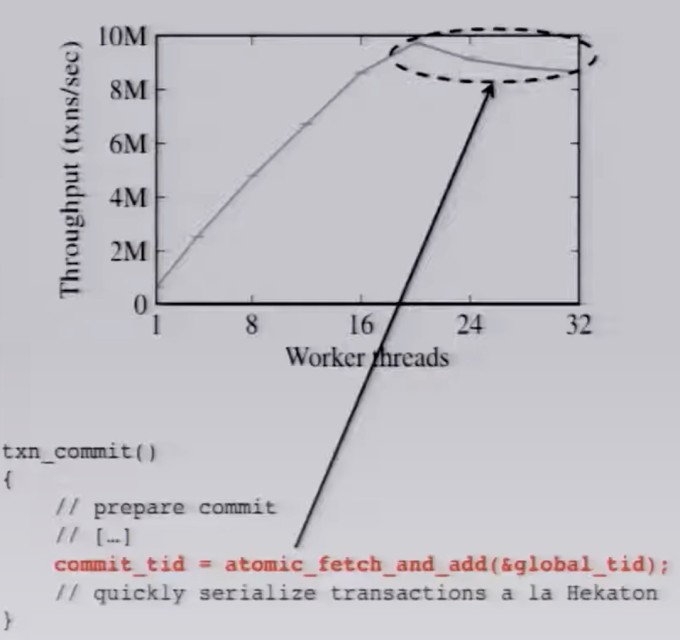
而全局有序的tso是保证isolation的充分条件但非必要条件,比如工业实现中,cockroachdb和tidb的commit ts都可以通过分析事务间的依赖关系来计算出来,我们实际上只关心冲突事务的order。 Silo提出了一种能在多核系统扩展的事务模型,不依赖于严格有序的全局时钟,基于OCC。
Introduction
Silo评估了一些同类系统的实现
单机引擎上:
- Masstree: B tree与Trie tre的结合。也是Silo的选择
- PALM: prefetch, SIMD 不太了解这玩意,有空看下(逃
- BW-Tree: delta实现的多版本,
事务实现上:
- Hekaton:SQL Server的引擎。依赖全局有序的tso;而且因为读的时候会"冒险读",也就是读到其他事务未提交的数据,形成commit-dependency,所以需要把自己的read-set发布到share-memory
- DORA:数据分区。 没看过,到时看下
- H-Store:同数据分区,跨分区事务糟糕。VoltDB是其一个工业实现
而Silo的实现下,既不需要全局有序tso,读操作也不需要写share-memory,也不有数据分区,每个worker线程都可以访问全部数据。
Implementation
Silo的核心实现其实是三个点:
- epoch base
- 将数据状态embadding到tid中
- commit protocol
epoch base
Silo将时间切分成一个个epoch,一个epoch内的所有事务都结束了,才能一起响应给客户端。这里是严重牺牲了RT来提升throughout,对有交互式需求的应该很难接受。(后面又发了篇silor来解决这个问题,OSDI ‘14)
但是对GC和snapshot read友好。
epoch有两个,global和per worker
Transaction ID
tid占64位,可以原子更新。分为三部分:epoch、sequance、status 其中sequance是epoch内的递增序号。 status有bit,分别标识:锁标记、是否是最新数据、删除标记。
tid是计算出来的,而不是通过中心化的分配器,计算规则有三个:
- 比read-set和write-set中的所有record的tid要大
- 比worker上一次分配的tid大
- 属于current epoch
大多数情况下,tid反映serial order,但并不总是如此。 比如如果t1写了一个数据,然后t2读到了,那么t1.tid < t2.tid (因为第一个规则 而如果t1读了一个数据,后续t2覆盖了该数据,那么无法判断两个tid谁大。也就是说tid无法反映anti-dependency.
Commit Protocol
Silo实现的是Serializable隔离级别,基于OCC,所以需要在validation阶段对read-set进行检验。

主要分三4个阶段:
- lock write set. 前面说lock status是embadding到tid里的,这里就是直接一个CAS更新状态位
- get global epoch. 要有fence,避免re-order
- validation. 检测read-set中的数据行的tid是否与之前读的时候一样。(被上锁也算)
- install write. validation通过,计算出一个tid(计算规则上面说过了),install write-set
如何证明这是Serializable的呢?论文认为这是commit protocol可以等价为S2PL: 在validation阶段确认整个过程中read-set没有被修改or即将被修改(有lock也会导致validation失败),所以读过程等价于加了读锁 而第一阶段对write-set上锁就相当于加写锁。
然后举了个具体的例子来说明避免write-skew问题:

如果t1的validation通过,那么t1后续一定会提交,所以反推一下,如果t1的validation通过,t2的validation会不会通过,如果会,则会出现A5B异常。 如果t1的validation通过,那么其对y的加锁肯定已经发生了,所以y的情况有两种可能:
- y的tid上面有锁:当t1validatiton通过但还没有install write时
- y的tid被更新成了新的epoch+sequance:当t1的validation通过且已经install 无论是哪种情况,都会导致t2的validation失败。故其会检测到rw-anti-dependency
What’s more
Phantoms
避免幻读的一个办法是存下predication和results,在validation的时候用predications重读,看与之前的results是否一样。
而Silo采用的方法是B Tree节点版本号校验的方式。B Tree节点在发生结构变动(比如插入删除一条数据)时,会更新节点版本号,如果版本号发生了变更,对这个节点的谓语读很有可能会发生幻读。所以validation主要是校验每个节点的版本号。 这里是提高了一些false-positive的概率,但是比用predication重读的开销要低
GC
没啥说的,就是Epoch-Base的GC。参考RCU
下一步阅读
- H-Store
- silor
- PALM